

EITAB : Extraction d’infos textuelles pour alimenter des bases
PEPS CNRS_PSL EITAB
Extraction d’informations textuelles pour alimenter des bases de données automatiquement, transferts d’information et évolution des thésaurus.
PEPS CNRS_PSL EITAB
En collaboration avec le LATTICE et l’INAR MIG, il s’agit d’extraire des champs de caractères de textes structurés en catalogue afin d’alimenter des tableurs pour nos bases et nos atlas. Les tests portent actuellement sur les CAG (cartes archéologiques de la Gaule)
La coopération entre chercheurs archéologues, linguistes et informaticiens, vise à concevoir et valider un traitement automatisé des corpus, de façon à réduire le temps d’intervention, accroître la fiabilité des résultats et faciliter le partage des données en interdisciplinaire (traitements statistiques, historiques, thématiques,...) : autrement dit, améliorer l’environnement d’étude et de recherche de l’archéologue.
Des objectifs gradués
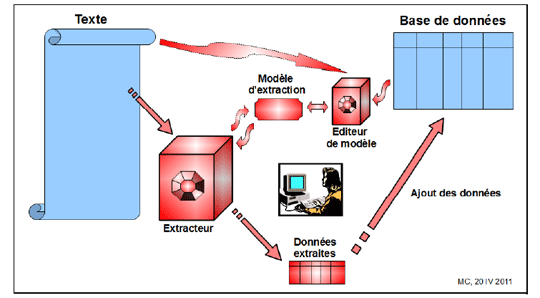
Que pouvons-nous récupérer automatiquement pour alimenter nos bases de données ? Existe-t-il des outils sur le marché ? _ Nous sommes partis d’un constat, nous avons - d’une part un thésaurus assez précis qui se présente sous forme de listes de valeur associées aux rubriques de nos bases de données - d’autre part des catalogues de sites sous forme papier ou numérique associés à des thèses ou à des publications.
Nous avons donc commencer par extraire des données simples : Lieux, datation, structures, références bibliographiques... Nous avons ensuite essayé d’extraire des chaînes de caractères identiques à celle de notre thésaurus et là nous nous sommes heurtés à deux types de difficultés : - celle de trouver un logiciel auto apprenant qui le permette et il n’en existe pas de commercialiser. - résoudre le problème de l’évolution de la recherche et de l’adaptation du vocabulaire à de nouvelles interprétations, ceci sur le temps long. - Surmonter le handicap d’un vocabulaire peu codifié et d’une communauté scientifique qui soigne ses textes, donc évite les répétitions, joue sur les synonymes et les structures de phrases, rien à voir avec les textes de biologie ou de pharmacie sur lesquels portent d’abord ce type d’étude.
Analyses de catalogues monétaires
Nous avons d’abord travaillé sur des textes très structurés comme les catalogues monétaires. Ceux-ci comprennent - un titre, une description de chaque face de la pièce, une bibliographie - puis une série de monnaies avec un numéro d’inventaire, un alliage et des mesures de poids de diamètre, d’épaisseur, une provenance. _ Une fois bien repérée la structure du document, le découpage se fait assez aisément - La dernière étape reste leur intégration dans la base de données.
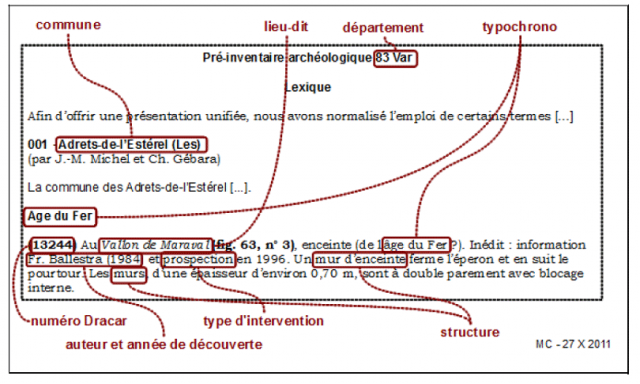
Analyse d’une carte archéologique de la Gaule
Dans un deuxième temps, nous avons choisi des volumes de bibliographies commentées classées par communes de provenance et avons testé divers outils dessus. Nous avons actuellement défini une chaîne d’outils d’analyse et nous sommes en train de les installer sur deux machines afin de voir si on peut passer de l’expérimentation à la production. L’étape à venir sera l’analyse complète d’un ouvrage et notre ambition est d’intégrer cet outil de recherche et d’extraction à nos publications en ligne.